中古寫本資料庫(DMCT)第一版說明
序言
「中古佛教寫本資料庫編碼」專案(DMCT)是一個的合作案,由根特大學佛學研究中心(Christoph Anderl主持)與中華佛學研究所(洪振洲合作主持)合作,林靜慧執行,Marcus Bingenheimer、張伯雍擔任顧問。
「中古佛教寫本資料庫編碼」專案(從2015開始)是一個持續進行的專案,雖然資料並不完全,但我們還是決定先把資料庫試用版公開。資料庫的內容主要是至今為止已被標記過的敦煌寫本數位版與所見異體字資料庫,另外還有一些研究結果將會陸續公佈,包括:中古漢語的文法與句子分析(目前已從700個例句中,分析統計出750 個LMC功能詞)、敦煌寫本方言的通假字資料等等。
除了由弗蘭德研究基金會、根特大學、中華佛學研究所/DILA與天竺基金會等單位提供資助,由林靜慧執行完成的資料庫(DMCT)之外,Marcus Bingenheimer也提供了他主持的「敦煌漢文佛教寫卷點校」專案的研究成果(2014-2017,Chan Buddhist Texts form Dunhuang,由中華佛學研究所資助,張伯雍執行),其中四種文獻已出版成書:《早期禪宗文獻四部 —— 以 TEI 標記重訂敦煌寫卷:楞伽師資記,傳法寶紀,修心要論,觀心論》[1],關於該專案的詳細說明,可以參見這裡。
DMCT專案(2015-)中,選擇哪些寫本進行數位化,是依照主持人的研究興趣與GCBS正在進行的博士研究計畫。最初這個專案的研究方向是語言學,所以選了一些語法偏向白話和口語的敦煌寫本。隨著專案的持續進行,研究的焦點漸漸轉移到了字體變形方面——也就是異體字研究。因此,本資料庫還包含了從數位化寫本中提取出的異體字資料庫。這個異體字資料庫的數據量,隨著專案的持續進行,也在不停的增加。到目前為止,異體字資料庫已經收錄了超過32.000個異體字型,它們大都能夠與來源寫本連結。使用者在進入異體字資料庫(Databases/Variant)時,為了得到更好的性能,因此需要先載入所有的異體字資料,這個過程會花一點時間,請耐心等候。
在寫本數位版中,異體字有三種呈現方式:第一種,異體字為Unicode已錄之字,則記錄在「數位文字摹本」,而將正字放在「標準字體化版」的相對位置上。第二種,異體字為台灣《異體字字典》(Dictionary of Chinese Character Variants)已錄之字,則在「數位文字摹本」的連結視窗中引用其字型。第三種,異體字為專案新增之字,則在「數位文字摹本」的連結視窗中呈現截取自寫本之字型圖。Chan Buddhist Texts form Dunhuang與DMCT是各自進行的專案,前者為了出版成書,所以在處理專案新增之字時,採用的是該專案模仿寫本繪製的楷體字圖。
如何使用資料庫?
本資料庫提供了一系列重要的中古漢語寫本的標記版本,與之前的其他版本不同,它們經過仔細的標記,盡可能忠實的呈現寫本的文字特徵。有時我們會標記幾篇內容相同而版本不同的寫本,此時我們會作簡單的校對,在必要的地方加上註解,說明它們之間的差異,或是在文字判定有疑慮時,加上詳細的說明(遇到有註解的數字,可以點按它,以連結到註解內容;看完註解,只要再次點按註解的數字,就會再跳回本文)。
本資料庫的文檔皆是採用TEI標準來標記的XML檔,它們的呈現方式是「數位文字摹本」與「標準字體化版」對照的HTML檔。「數位文字摹本」保留了寫本的文字特徵,例如:異體字、塗改字、重文符號、簡寫符號等;「標準字體化版」呈現的是乾淨清楚、加上現代標點、較容易閱讀的模式。在「數位文字摹本」中,只要指鼠標指到標有淺橙色的字,它的異體字就會出現在螢幕右上角的浮動視窗中。這個視窗裡的異體字,主要是引用《異體字字典》(Dictionary of Chinese Character Variants),還有一些是截取自寫本的專案新增異體字。另外還有一些標記的呈現方式,在每個頁面的開頭都有詳細說明。
本資料庫中的某些標記版本,已被作為新版本的材料或是翻譯的底本而出版(關於〈破魔變〉的出版計畫[2] ,可以參見這裡),還有一些相關的研究論文也已經或即將出版。[3]
本專案將敦煌寫本的異體字放在「Database / Variants」,這個程式的設計與編寫是由Christian Bell和Jan Schrupp負責。本專案希望將寫本數位化編碼的同時,盡可能的將寫本中的異體字收集起來,並開發一種工具,可以幫助讀者閱讀富含少見異體字的敦煌寫本。我們希望在研究敦煌文獻時,這個資料庫可以成為有用的工具。目前,我們還在資料庫中安裝高級的搜索功能(在「Database/ Bibliography」中已經完成),以及導入William H. Baxter / Laurent Sagart提供的關於文字的歷史知識。
本資料庫是一個正在進行的專案,其中必定會有錯誤的解讀或是其他問題,為此,我們打算在資料庫中加進「互動」的功能,以便能夠記錄讀者的註解與改正。目前,讀者已經可以在「comment box」的框中加入註釋。在此之前,讀者必須先在本網站註冊為用戶。已註冊的用戶,將可以收到更新的訊息。
本資料庫打算採用「開放」的形式。因為敦煌文獻裡,有許多很有意思的文獻,它們沒有被記錄在經典中,而且數量非常龐大,但是,目前只有一小部分文獻能夠被選出來進行數位化編碼。因為這種數位化編碼工作必須耗費大量的時間,我們需要許多有專業知識且有極大耐心的編碼者。
此外,本資料庫也會為了配合正在進行的研究計畫而調整:目前基於與四川大學合作的研究項目,我們正在實做一套工具,用來標記禪宗的成語與諺語和其互見現象。
過去兩年裡,本資料庫也被用在碩士班的課程中,例如:與學生們一起翻譯與註釋〈太子成道經〉,還有為期三個月的碩士生實習。因此,本資料庫在教授高年級碩士生與博士生的課程中,具有教學功能。(根特大學博士研究計畫的選擇可以看這裡)
關於數位化編碼所採用的技術與設計
在DMCT的專案中,我們採用TEI的標準,對敦煌寫本進行數位化編碼。本專案基本上沿用Marcus Bingenheimer在「敦煌漢文佛教寫卷點校」專案制定的框架,並做了一些調整。
 使用oXygen 進行編碼工作(上圖為Pelliot 2187〈破魔變〉的一小部分)
使用oXygen 進行編碼工作(上圖為Pelliot 2187〈破魔變〉的一小部分)
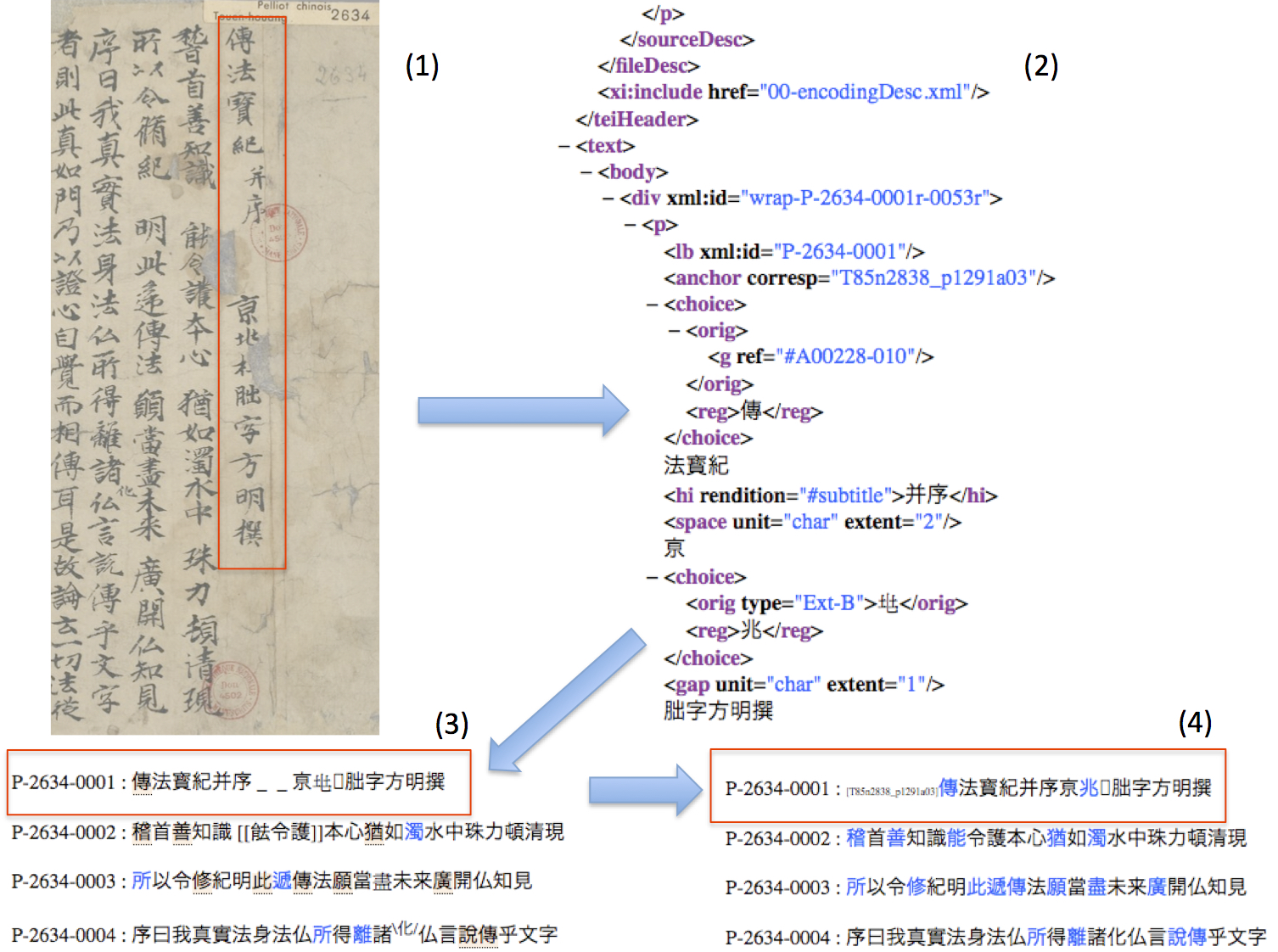
以寫本Pelliot 2634第一行的編碼與轉檔方式為例:
(1) 紅色的框表示寫本複印圖片的第一行;
(2) 顯示的是在oXygen上的XML檔:使用TEI標記,將第一行進行編碼;
(3) 紅色的框表示XML轉成HTML所呈現的網頁:保留了寫本文字特徵的「數位文字摹本」;
(4) 紅色的框表示XML轉成HTML所呈現的網頁:將寫本文字正規化之後的「標準字體化版」,這個版本是進一步研究寫本的基礎,例如:註釋、翻譯、語法分析等等。
目前的技術框架如下:
-
在早期的資料庫版本,我們使用eXist 資料庫來儲存所有的XML檔案,但是在大約一年前,我們改用MySQL。MySQL是一種由資料表格組織而成的關聯式資料庫;
-
MySQL可以使用各種不同的儲存引擎;我們針對不同的資料表格分別使用InnoDB或MyISAM;
-
對於為全文搜索而設計的表格,我們使用MyISAM。其他如使用者管理等資料表則使用InnoDB;
-
程式邏輯方面使用PHP實做,使用物件導向程式設計(OOP)以及其他如PDO等新介面;
-
網頁呈現使用CSS來設計;
-
使用HTML5以及JavaScript支援網頁更深層的設計;
-
由於我們要處理XML檔案,但是資料庫本身並不儲存XML檔,所以我們做了XML檔的匯入與匯出功能;
-
舊資料庫所有的功能在新系統中都已經建置完成,此外還增加了一些新的功能,例如:異體字模組,所有模組都有的註解功能,複雜的輸入遮罩(Input Masks),還有更先進的用戶管理,多個搜索功能(包括全域搜尋)。
-
新系統明顯更快、更穩定,而且更容易增加新功能(例如:輸入遮罩、分析模組)以及除錯;
-
開發過程已經過優化:程式原始代碼使用版本控制系統(Subversion)進行管理,部署上線程序也已自動化。
儘管這個資料庫目前還是有一些缺點或錯誤,但我們還是非常希望您可以愉快的使用這個測試版!
致編輯者們
Christoph Anderl
註解:
-
[1] Bingenheimer, Marcus (馬德偉) and Chang Po-Yung 張伯雍 (eds.): Four Early Chan Texts from Dunhuang – A TEI-based Edition 早期禪宗文獻四部 —— 以TEI標記重訂敦煌寫卷:楞伽師資記,傳法寶紀,修心要論,觀心論. Taipei: Shin Wen Feng 新文豐. 3 Vols. Vol. 1: Facsimiles and Diplomatic Transcription 摹寫版 (ISBN: 978-957-17-2274-0), Vol. 2: Parallel, Punctuated and Annotated Edition 對照與點注版 (ISBN: 978-957-17-2275-7), Vol. 3: Calligraphy Practice 抄經版 (ISBN: 978-957-17-2276-4).
-
[2] 林靜慧, Anderl, C., and 洪振洲. <破魔變>中英對照校注 [Pò Mó Biàn Critical Edition with Annotated Translations into Modern Chinese and English]. Taipei: Fagu wenhua 法鼓文化, 2017.
-
[3] For example: Anderl, C. 2018. “Linking Khotan and Dūnhuáng: Buddhist Narratives in Text and Image.” Entangled Religions 5: 250-311. Anderl C. and Sørensen, H. Northern Chán and the Siddhaṁ Songs. Forthcoming in Dūnhuáng and Beyond: Texts, Manuscripts, and Contexts – In Memory of John McRae, edited by C. Anderl and C. Wittern. Numen Series. Leiden: Brill. Anderl, C. Metaphors of ‘Sickness and Remedy’ in Early Chán Texts from Dūnhuáng. In Reading Slowly: A Festschrift for Jens E. Braarvig, edited by L. Edzard, J. W. Borgland, and U. Hüsken, pp. 27-46. Wiesbaden: Harrassowitz.